
海贼王に俺はなる
Python3简单爬虫——爬取豆瓣图片
原创 python pengchen 2017, February 07
网络爬虫,也称为蜘蛛程序(Spider)。网络爬虫是一个自动提取网页的程序,是搜索引擎的重要组成部分。作为爬虫来讲,就是尽可能多和快的给搜索引擎输送网页,实现强大的数据支持。
网络爬虫是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
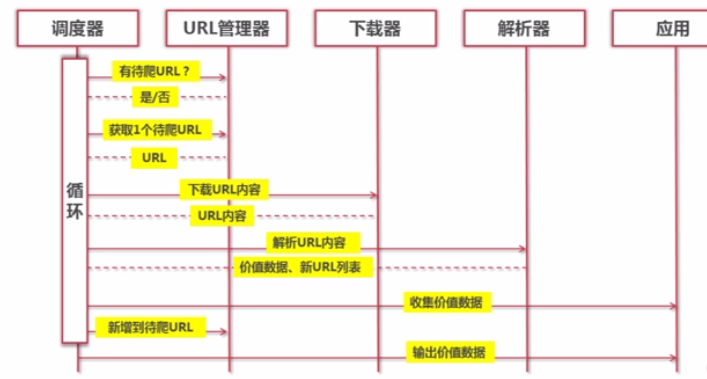
SpiderMain.py
import UrlManager,HtmlDownloader,HtmlParser,FileOutputer
class SpiderMain(object):
def __init__(self):
self.urlManager = UrlManager.UrlManager()
self.htmlDownloader = HtmlDownloader.HtmlDownloader()
self.htmlParser = HtmlParser.HtmlParser()
self.fileOutputer = FileOutputer.FileOutputer()
def carry(self,root_url):
count = 1
self.urlManager.add_new_url(root_url)
while self.urlManager.has_new_urls():
try:
url = self.urlManager.get_new_url()
print("SpiderMain正在准备爬取:"+url)
html_data = self.htmlDownloader.download(url)
new_urls = self.htmlParser.parser(html_data)
self.urlManager.add_new_urls(new_urls)
filecount = self.fileOutputer.file_output(html_data)
print(url+"中爬取了"+str(filecount)+"张图片")
if count ==1000:
break
count +=1
except Exception as error:
print("SpiderMain Exception error:",error)
print("爬虫爬取URL数:"+str(count))
if __name__ == "__main__":
root_url = 'https://www.douban.com/'
spider = SpiderMain()
spider.carry(root_url)
print("爬虫入口URL为:"+root_url)
else:
print("正在执行其他模块")
UrlManager.py
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_urls(self,urls):
# print("UrlManager urls:"+str(urls))
if urls is None or len(urls)==0:
print("UrlManager urls is None or len=0")
return
# print(type(urls))
for url in urls:
self.add_new_url(url)
def add_new_url(self,url):
if url is None:
print("UrlManager url is None")
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def has_new_urls(self):
return len(self.new_urls) != 0
HtmlDownloader.py
import urllib.request
class HtmlDownloader(object):
def download(self,url):
if url is None:
print("HtmlDownloader url is None")
return None
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
if response.getcode() != 200:
print("HtmlDownloader download error:"+response.getcode())
return None
data = response.read()
# data = data.decode("utf-8")
return data
HtmlParser.py
from bs4 import BeautifulSoup
import re
class HtmlParser(object):
def geturls(self,soup):
new_urls = set()
links = soup.find_all('a')
# print(links)
for link in links:
try:
new_url = link['href']
except Exception as error:
print("HtmlParser geturls:",error)
new_urls.add(new_url)
# print(new_urls)
return new_urls
def parser(self,html_data):
if html_data is None:
print("HtmlParser html_data is none")
return
soup = BeautifulSoup(html_data,'html.parser',from_encoding = 'utf-8')
new_urls = self.geturls(soup)
return new_urls
FileOutputer.py
from bs4 import BeautifulSoup
import urllib.request,os,re
class FileOutputer(object):
# 下载进度
def process(self,a, b, c):
# a: 已经下载的数据块
# b:数据块的大小
# c:远程文件的大小
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f%%' % per)
def savefile(self,path):
filepath = "C:\\Users\\Administrator\\Desktop\\spider"
if not os.path.isdir(filepath):
os.mkdir(filepath)
pos = path.rindex('/')
t = os.path.join(filepath, path[pos + 1:])
return t
def file_output(self, html_data):
file_count = 0
soup = BeautifulSoup(html_data, 'html.parser', from_encoding='utf-8')
links = soup.find_all('img')
for link in links:
# print(str(link))
try:
img_url = link['src']
urllib.request.urlretrieve(img_url, self.savefile(img_url),self.process) # 下载到本地
print(str(img_url)+"下载成功\n")
file_count +=1
except Exception as error:
# print(str(link))
print(str(img_url) + "下载失败",error)
return file_count
感谢您的阅读